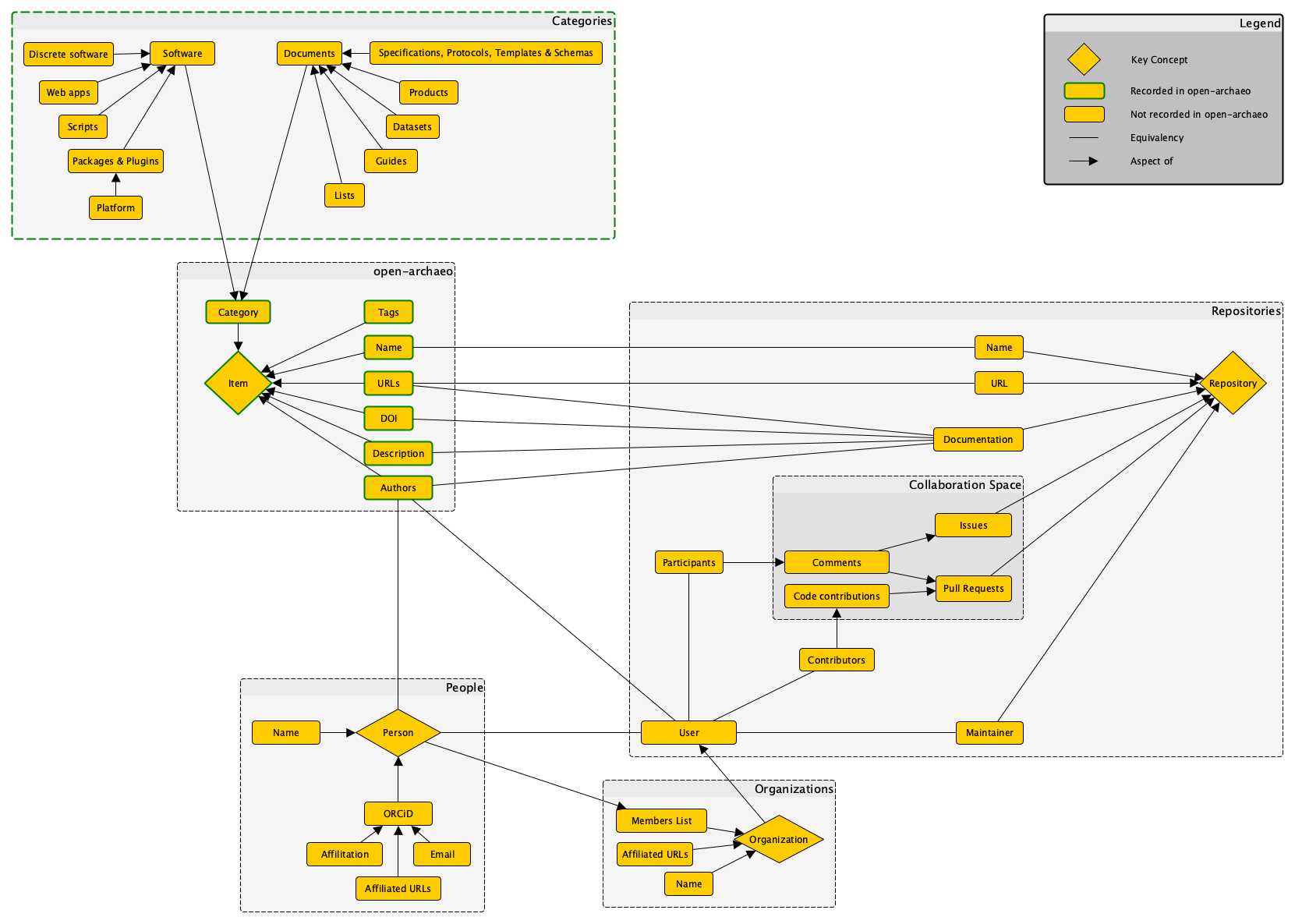
I’m using this post to draw out some thoughts that I feel are coherent in my mind but I struggle to communicate in writing. The general topic is the notion of formality, and how it is expressed in data work and data records.
In a management sense, formality involves adhering to standard protocol. It involves checking all the boxes, sticking to the book, and ensuring that behaviour conforms to institutional expectations. In this way, bureaucracy is the essence of formality. By extension, formality is a means through which power is expressed, in that it binds interactions to a certain set of acceptable possibilities. In effect, formality renders individual actions in subservience to a broader system of control.
But formality is also useful. Formality reduces friction involved in transforming and transmitting information across contexts. Any application that implements a formal standard can access and transmit information according to the standard, which reduces cognitive overhead on the part of actors responsible for processing information. They relocate creative agency upstream, towards managers of data and of labour, who make decisions regarding how other actors (human and non-human actors alike) may interact with the system before they ever occur. This basically manifests itself in workflows, which are essentially disciplined ways of working directed towards targeted outcomes (I wrote about workflows in a 2021 paper and in my dissertation, which draws from Bill Caraher’s contribution to Critical Archaeology in the Digital Age, among other work he’s written on the topic). To be clear, I do not mean to imply that adopting workflows constitutes a negative act. An independent scholar may apply a workflow to help achieve their goals more effectively and efficiently, and empowers them to get the most out of the resources at their disposal. However, one of the key findings from my dissertation is that when applied in collective enterprises, they tend to genericize labour and data for the purpose of extraction and appropriation, which is understood to be an ordinary aspect of archaeological research, as is evident by how actors performing genericized labour internalize this as part of their work role.
Developing a workflow essentially entails adopting and enforcing protocols and formats, which are series of documented norms and expectations that ensure that information may be made interchangeable. Protocols are standards that dictate means of direct communication, and formats are standards that dictate how should be stored. Forms are interfaces through which information is translated from real-world experiences into standardized formats.
Formal data are information whose variables and values are arranged according to a formally-defined schema. A formal dataset comprises a series of records collated in a consistent manner, motivated by a need, desire or warrant to render them comparable. The formally-defined schema makes this potential for comparison much easier. A common means of representing formal data is through tables, which are comprised of rows and columns. Each row represents a record, and each column a variable that describes a facet of each record. The values recorded for each variable constitute observations or descriptive characterizations pertaining to the object of each record. One can therefore determine what kinds of structured observations were made about a recorded object by finding the values located at the intersection of records and variables (i.e., individual cells in a table). Each record relates to a set of variables applied to the whole set and documented in the schema.
In its most extreme, formality entails a realm of total control, where all information is collected and processed according to an all-encompassing model of the world. It is not coincidental that models are the primary outlooks through which both managers and computer systems engage with the world. It has been the dream of bureaucrats and computer scientists alike to develop such systems (see the work of Paul Otlet, Vanevar Bush, and the weirdly techno-libertarian crowd associated with structured note-taking and personal knowledge management). Nor is it a coincidence that formality is a requisite aspect of both bureaucracies and computers. Computational environments and bureaucracies both effectively capture and maintain institutional power dynamics.
In some cases, such as with text boxes, the variable may be precisely defined by the values are left open-ended. However, users are still expected to provide certain kinds of information in these fields (I remember at a conference in 2019, Isto Huvila (whose work on archaeological records management is also a great source of inspiration) referred to these as “white boxes”, which conveys their literal appearance and is a clever and ironic play on words referring to the notion of “black boxes” that hide the intricate details of a process behind an opaque connotative entity). In this sense, the standards are thus mediated by social and professional norms, but exist nonetheless. This reflects the fact that social and professional norms, standards, and expectations will never go away, they are fundamental aspects of communication and participation within communities.
The million dollar question nowadays (at least in my own mind) is how can we create information infrastructures that strike a balance between the need to transmit information succinctly between computers via the web, and the capability to share context and subtext whose significance originate in the gaps between recorded information and which gain meaning only in relation to the shared experience of communicating agents as members of a social or professional community?